Sort - 힙정렬(heap sort) - 2
이번 시간에는 heap과 heapify연산을 이용해서
어떻게 heap 정렬을 할것인지 알아 볼것이다.
그 전에 정렬을 하기 위해서는 heap을 만들어야한다.
정렬할 1차원 배열을 complete binary tree로 해석한다
tree로 만든다는 것이 아니라 개념적으로 받아들인다는 뜻이다.
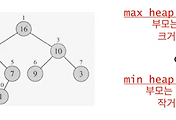
complete binary tree는 heap property를 만족하지 않기때문에
heap은 아니다.
그러므로 부모가 자식보다 크다 라는 조건이 자동으로 성립되지 않는다.
따라서, 정렬의 첫번째 조건은 complete binary tree을 heap으로 만드는 것이다.
leaf가 아닌 그 다음 레벨의 노드에서부터
heapify 연산을 통해서 heap으로 만들어준다.
1 2 3 4 | BUILD-MAX-HEAP heap-size[A]<-length[A] for i <- |length[A]/2| downto 1 do MAX-HEAPIFY(A,i) | cs |
따라서 슈도코드는 다음과 같이 작성된다.
슈도 코드가 간단하게 나오는 이유는 미리 HEAPIFY 연산을 구현했기 때문이다.
힙을 만드는데의 시간 복잡도는 다음과 같다.
HEAPIFY연산의 시간 복잡도는 log(n) 이다.
그런데 for 문이 n/2 돌기 때문에 n/2*log(n)이며 빅 오로 표기하면
O(n*log(n))이 된다.
이는 루트 노드만 고려하여 상당히 러프하게 계산한 것이기 때문에,
정확하게 계산한다면 시간복잡도는 O(n)이 된다.
일단 힙을 만드는데는 n의 시간이 걸리지만
정렬을 하는데 시간이 nlogn이기 때문에
결과적으로 nlogn의 시간복잡도가 나온다.



위의 그림은 tree를 heap으로 만드는 과정이다.
따라서 힙 정렬은 다음과 같은 순서를 따른다.
1) 주어진 데이터를 힙으로 만든다
2) 힙에서 최대값(루트)을 가장 마지막 값과 바꾼다.
3) 힙의 크기가 1 줄어든 것으로 간주한다. 즉, 마지막 값은 힙의 일부가 아닌것으로 간주한다.
4) 루트 노드에 대해서 HEAPIFY(1)한다.
5) 2~4번을 반복한다.
데이터를 힙으로 만들면 인덱스 0의 값이 가장 최대값 이므로 마지막 값과 바꾼다.
그리고 마지막값은 정렬된 값으로 간주하고 더 이상 신경쓰지 않는다.
그렇게 줄여나간다면 결국 정렬된 상태의 배열이 완성된다.
1 2 3 4 5 6 | HEAPSORT(A) BUILD-MAX-HEAP(A) // O(n) for i <-heap-size downto 2 do // n-1 times exchange A[1] <-> A[i] // O(1) heap_size <- heap_size -1 // O(1) MAX-HEAPIFY(A,1) // O(log(n)) | cs |
완성된 힙 정렬의 슈도 코드이다.
MAX-HEAPIFY의 시간복잡도 logn의 밑은 2이다.
따라서 총 시간 복잡도는 nlogn(밑은 2)가 된다.
출처 : 부경대 권오흠 교수님, 영리한 프로그래밍을 위한 알고리즘
'알고리즘 문제풀이' 카테고리의 다른 글
| [알고리즘] Sort - 정렬의 Low Bound (0) | 2017.04.19 |
|---|---|
| [알고리즘] Sort - Heap의 응용, 우선 순위 큐(Priority queue) (0) | 2017.04.19 |
| [알고리즘] Sort - 힙정렬(heap sort) - 1 (0) | 2017.04.19 |
| [알고리즘] Sort - 퀵정렬(Quick sort) (0) | 2017.04.19 |
| [알고리즘] Sort - 합병정렬(Merge sort) (0) | 2017.04.19 |



댓글