Sort - 퀵정렬(Quick sort)
퀵 정렬은 합병 정렬과 동일하게 분할정복법을 사용하나
방법에서 차이를 보인다.
퀵 정렬에서는 정렬할 데이터가 주어지면
하나의 값을 기준값(pivot)으로 사용하여 정렬을 실행한다.
어떤 값을 기준값으로 잡는냐가 퀵정렬 성능의 관건이다.

1) 분할
하나의 값을 피봇으로 선정 한 후, 데이터들을 피봇보다 큰 값과 작은값으로 분류한다.
그렇기 때문에 합병정렬과 같이 반으로 갈라지는 것을 보장하지 않는다.
그렇기 때문에 기준값에 따라 최악/최선의 상황이 나뉜다.
2) 정복
분할한 양쪽을 각각 재귀로 퀵 정렬한다.
3)합병
할일이 없다.
이미 분할과 정복 과정에서 정렬이 완료되었기 때문이다.

위의 과정들을 표현한 그림이다.
파티션 후에는 재귀적으로 정렬해주면 되기때문에
결국 퀵 정렬에서 중요한것은 파티션이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 | quickSort(A[],p,r){ if(p<r) then{ q = partition(A,p,r);// 분할 quickSort(A, p, q-1);// 왼쪽 부분배열 정렬 quickSort(A, q+1, r);// 오른쪽 부분 배열 정렬 } } partition(A[], p, r){ 배열 A[p...r]의 원소들을 A[r]을 기준으로 양쪽으로 재배치하고 A[r]이 자리한 위치를 return } | cs |
퀵 정렬에 대한 슈도 코드이다.
배열 A의 인덱스 p에서 r사이에 있는 데이터를 정렬한다.
여기서도 조건문으로 p가 r 보다 작은 경우에만 알고리즘이 실행되도록 한다.
다음으로 partition이라는 함수가 피봇값을 기준으로
전체 데이터를 나눠주고 피봇 인덱스를 반환하는 역할을 한다.
따라서, q는 피봇이 된다.
[p, q-1]은 배열의 왼쪽 부분, 작은 값이고
[q+1,r]까지는 배열의 오른쪽 부분, 큰 값이다.
재귀적으로 quickSort함수를 호출하여 정렬해준다.

정렬은 재귀로 동작하기 때문에
실제로 자세히 봐야하는것은 partition함수이다.
여기에서는 인덱스의 마지막 값을 기준값으로 설정하도록 하겠다
기준값을 중앙으로 옮기면 불필요한 연산이 발생하므로
기준값 앞에서 작은값과 큰값을 정렬한 후
마지막에 기준값을 원래 위치로 이동시킨다.
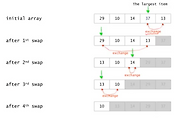
때문에 위의 그림에서 j를 기준으로 설명하자면
현재 인덱스 j의 값이 기준값보다 크다면 j 를 증가시켜 다음값을 보러가면된다.
그러나 인덱스 j 의 값이 기준값보다 크다면 앞쪽으로 보내야하는데,
이때 i값을 1 증가 시킨 후 그 값과 교환을 해준다.


위에서 본 과정을 나타낸 그림이다.
여기서 기준값은 마지막 인덱스인 15이다.
i와 j를 증가시키며 첫번째 인덱스부터 기준값과 비교하면서 정렬을 수행한다.
모든 정렬이 완료되면 인덱스 i+1의 값과 기준값의 위치를 바꿔준다.
1 2 3 4 5 6 7 8 9 10 | Partition(A, p, r){ x<-A[r]; i<-p-1; for j<-p to r-1 if A[j] <= x then i<-i+1; exchange A[i] and A[j]; exchange A[i+1] and A[r]; return i+1; } | cs |
Partition을 슈도코드로 나타내었다.
앞서 설명한 위치 변환과 인덱스 증가로 정렬을 완료하고
마지막으로 피봇의 인덱스를 리턴해준다.

파티션을 하는데 걸린시간이 얼마인지 생각해보면
모든 데이터를 한번씩 비교하면 되므로 n이 된다.
정확하게 말하자면 데이터의 개수가 n개일때 n-1번의 비교가 이루어지게된다.
합병 정렬보다 시간복잡도가 더 복잡한데
합병 정렬이 2개로 나뉘는것과 달리
퀵 정렬은 데이터가 고르게 나누어지지 않기때문이다.
먼저 최악의 경우 부터 생각해보면
모든 배열이 정렬되어있을 때, 기준값이 최대/최소 값일 때,
최악의 시간 복잡도가 발생한다.
분할은 0개와 나머지 전체로 나누어지므로 결국 데이터는 아무변화가 없고
똑같은 루틴이 반복되므로 시간복잡도는
O(n^2)가 된다.
거꾸로 최선의 경우는 항상 절반으로 분할되는 경우이다.
이 때는 merge 정렬과 동일한 시간을 가지며
원리 또한 같다.

다른 알고리즘보다 대체로 빠르기때문에 퀵 정렬이라는 이름이 붙었다.
그렇지만 최악의 경우에는 n^2의 느린 속도를 보여줬는데
왜 퀵 정렬이 다른 알고리즘 보다 빠른걸까
최선의 경우와 최악의 경우는 극단적인 케이스라서
실제적으로 일어나기 어려운 상황이다.
현실적으로 가정 했을 때,
n개의 데이터가 항상 9:1로 분할 된다고 하자.
한 페이즈 당 분할되는 시간을 구하면 항상 n이므로
전체 비교 연산은 트리의 깊이*n 이다.
트리는 대칭적이지 않으므로 가장 깊은 오른쪽 경로(최악의 경우)를 예로 들면
(9/10)^k * n = 1 이된다.
따라서 시간복잡도는 k = log9/10(n) 이 된다.
이 예가 의미하는것은 퀵 정렬의 성능은
파티션이 얼마나 밸런스있게 나뉘냐에 결정된다는 것이다.
극단적인 경우만 아니라면 퀵 정렬의 시간복잡도는 nlogn 이 되므로
실제로 상당히 빠른 정렬 방법이 된다.
평균 시간 복잡도는 생략한다.

마지막으로 기준값을 선택하는 방법에 대해 알아보자
우리는 마지막 값을 기준값으로 설정했지만 이는 그리 권장되지 않는다.
이미 오름 차순이나 내림 차순으로 정렬된 데이터일 경우
속도가 느려질수 있기 때문이고,
넘어온 데이터가 정렬 되어있을 경우는 상당히 높기 때문이다.
Median of Three는
첫번째/중간/마지막 인덱스의 값들을 각각 비교하여
이중에서 2번째 값을 피봇으로 설정하는 것이다.
이 방법을 이용하면 최대나 최소의 경우는 피할수 있지만
최악의 경우 시간 복잡도는 달라 지지 않는다.
마지막으로 기준값을 랜덤하게 선택하는 방법이다.
그렇게 되면 명시적인 최악의 경우가 사라지지만
주사위를 운이 나쁘게 굴린다면 계속해서 최소값만 걸릴수있다.
이 경우를 최악의 경우라고 할수있다.
출처 : 부경대 권오흠 교수님, 영리한 프로그래밍을 위한 알고리즘
'알고리즘 문제풀이' 카테고리의 다른 글
| [알고리즘] Sort - 힙정렬(heap sort) - 2 (0) | 2017.04.19 |
|---|---|
| [알고리즘] Sort - 힙정렬(heap sort) - 1 (0) | 2017.04.19 |
| [알고리즘] Sort - 합병정렬(Merge sort) (0) | 2017.04.19 |
| [알고리즘] Sort - 기본적인 정렬 알고리즘(선택,삽입,버블) (0) | 2017.04.19 |
| [알고리즘] Recursion의 응용 - 멱집합(power set) (0) | 2017.04.19 |


댓글