해싱(Hashing) - 1
해쉬 테이블은 다이나믹 셋을 구현하는 또 다른 방법이다.
일반적으로 해쉬 테이블은 탐색, 삽입, 제거 3가지 연산들의 시간 복잡도에 대해 애매한 부분이 있으나
적절한 가정하에서 평균적으로 O(1)의 복잡도를 가진다.
보통 최악의 경우에서는 O(n)이 된다.
(해싱을 사용하는 경우 정확한 복잡도를 계산하기 어려우므로 가정하게된다.)

해쉬 테이블은 해쉬 함수라는 특별한 함수를 통해 어떤곳에 저장할것인지 지정하는것을 말한다.
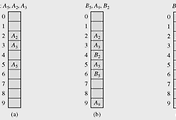
해쉬테이블은 큰 배열이라고 생각하면된다.
위의 그림은 0번지부터 m-1 번째까지, m개의 슬롯을 가지고 있는 해쉬 테이블이다.
h : U -> {0,1,2,3,4,5,6... m-1}
라고 할 때 U는 모든 가능한 키들의 집합을 말하며, m은 테이블의 크기를 뜻한다.
이때 키값을 넣으면 적절한 인덱스로 변환해주는 함수를 해쉬 함수(h)라고 한다.
예를 들어 가장 쉽게 해쉬 함수를 만들자면,
u를 양의 정수들의 집합이라고 가정하고, m을 테이블의 크기라고 했을 때
index = h(x) = x % m
위의 식과 같이 인덱스를 도출할 수있다.
이 해쉬함수를 적용하면 항상 0~m-1까지의 인덱스가 나오게 된다.
그러나 위와 같은 함수는 중요한 단점들이 많이 발생하므로 실제로 잘 사용하지는 않는다.

해쉬 함수를 사용하다보면 똑같은 위치에 데이터가 들어가는 경우가 있는데 이를 충돌(collision)이라고 한다.
즉, H(k1) = H(k2) 인 상황에 발생하는 것이다.
그렇다면 이런일이 발생하지 않게 하면 되는가라고 생각할 수 있지만,
일반적으로 |U|>>m 이므로 항상 발생이 가능하다(일대일대응함수(단사 함수)가 아님),
단사함수가 되려면 m(치역)이 U(정의역)보다 더 커야하기 때문이다.
만약 |K|>m이라면 당연히 발생한다.(여기서 k는 실제로 저장된 키들의 집합)
따라서 이러한 충돌을 피할수 없으므로, 이와 같은 상황이 발생 했을 때 해결 하기 위한 방법이 필요한데,
대표적으로 chaining과 open addressing이 그 예이다.

먼저 Chaining 부터 알아보자.
충돌이 일어나는 이유는 하나의 슬롯에 하나의 데이터만 저장할 수 있기 때문이다.
이를 예방하기 위한 Chaining의 개념은 간단한데,
각각의 슬롯에 저장되는 데이터를 연결리스트로 만들어서 많은 데이터를 저장할수 있게 하는것이다.
즉, 슬롯에는 첫번째 연결리스트의 주소값만 가지게 된다.
1) 키의 삽입
- 키 k를 리스트 T[h(k)]의 맨앞에 삽입 : 시간 복잡도 O(1)
- 중복된 키가 들어올 수 있고, 중복 저장이 허용되지 않는다면 삽입시 리스트를 검색해야 함
- 따라서 시간 복잡도는 연결리스트의 길이에 비례한다.
2) 키의 검색
- 리스트 T[h(k)]로 부터 키를 검색 후 삭제
- 시간 복잡도는 키가 저장된 리스트의 길이에 비례
3) 키의 삭제
- 리스트 T[h(k)]로 부터 키를 검색 후 삭제
- 일단 키를 검색해서 찾은 이후에 O(1) 시간에 삭제 가능

이 때, 최악의 경우는 모든 키가 테이블 상의 하나의 슬롯으로 해싱되는 경우이다.
- 길이가 n인 연결리스트가 만들어짐
- 따라서 최악의 경우 탐색 시간은 O(n) + 해쉬 함수를 계산하는 시간
그러므로, 평균 복잡도는 키들이 여러 슬롯에 얼마나 잘 분배 되느냐에 의해서 결정된다.
따라서 우리는 SUHA(Simple Uniform Hasing Assumption) 라고 가정하고 해싱을 진행하게 되는데,
이는 각각의 키가 모든 슬롯에 대해 균등한 확률로(equally likely) 독립적(independently)으로 해싱된다는 가정이다.
그러나 성능 분석을 위한 가정이므로 해시 함수는 deterministic하므로 현실에서는 불가능하다.
deterministic이란키가 해시함수에 적용되었을 때 특정한 인덱스로 적용될 확률은 1이고 다른 인덱스로 확률은 0이므로
인덱스에 대한 확률은 변하는것이 아니라 고정된다는 것이다.
각 슬롯에 저장되는 키의 평균개수를 Load factor라고 했을 때
Load factor = a = n/m
- n : 테이블에 저장될 키의 개수
- m : 해쉬 테이블의 크기, 즉 연결 리스트의 개수
위와 같이 식을 도출할 수 있다.
또한 연결리스트 T[j]의 길이를 n_j라고 한다면 E[n_j] = a가 되고
만약 n=O(m)이면 평균 검색 시간은 O(1)이다.
'알고리즘 문제풀이' 카테고리의 다른 글
| [알고리즘] 해싱(Hashing) - 3 (0) | 2017.05.10 |
|---|---|
| [알고리즘] 해싱(Hashing) - 2 (0) | 2017.05.09 |
| [알고리즘] Tree - 레드 블랙 트리(Red Black Tree) - 3 (0) | 2017.04.24 |
| [알고리즘] Tree - 레드 블랙 트리(Red Black Tree) - 2 (0) | 2017.04.19 |
| [알고리즘] Tree - 레드 블랙 트리(Red Black Tree) - 1 (0) | 2017.04.19 |

댓글